Research thread aims to propose, design, and validate assessment framework as a pivotal driver for the entire learning system.
Open-ended questions (constructed-response assessments in science education) and students’ written expressions across various genres and registers offer insights into original thoughts to specific topics and the application of disciplinary knowledge. Unlike other assessment types like multiple-choice items, these methods require responses in students’ own words. However, challenges exist in the scoring process marked by subjectivity and the substantial cost of human labor. The automation of scoring processes in such assessments, utilizing statistical predictive modeling and artificial intelligence-driven techniques, presents a promising avenue for enhancing efficiency.
In my research endeavors, I have proposed, designed, and refined techniques employing linear regression, machine learning based classifiers, and BERT to evaluate students’ writing levels, including their overall writing quality, reasoning efficiency, and expertise levels as my model labels. I have also advocated for the incorporation of features (textual: linguistic and semantic features; and student-related: cognitive levels of topical knowledge) into language models. Alternatively, large language models can be extended innovatively by integrating linguistic features, thematic attributes, and ontological perspectives to fine-tune the model so as to ensure that the model can effectively score students’ educational products based on these important features. 123
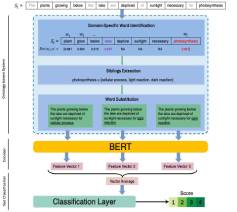
Extending a Pretrained Language Model (BERT) using an Ontological Perspective to Classify Students’ Scientific Expertise Level from Written Responses
Heqiao Wang, Kevin Haudek, Amanda Manzanares, and 2 more authors
International Journal of Artificial Intelligence in Education (in review) 2024
The complex and interdisciplinary nature of scientific concepts presents formidable challenges for students in developing their knowledge-in-use skills. The utilization of computerized analysis for evaluating students’ contextualized constructed responses offers a potential avenue for educators to develop personalized and scalable interventions, thus supporting the teaching and learning of science consistent with contemporary calls. While prior research in artificial intelligence has demonstrated the effectiveness of algorithms, including Bidirectional Encoder Representations from Transformers (BERT), in tasks like automated classifications of constructed responses, these efforts have predominantly leaned towards text-level feature, often overlooking the exploration of conceptual ideas embedded in students’ responses from a cognitive perspective. Despite BERT’s performance in downstream tasks, challenges may arise in domain-specific tasks, particularly in establishing knowledge connections between specialized and open domains. These challenges become pronounced in small-scale and imbalanced educational datasets, where the available information for fine-tuning is frequently inadequate to capture task-specific nuances and contextual details. The primary objective of the present study is to investigate the effectiveness of the established industrial standard pretrained language model BERT, when integrated with an ontological framework aligned with our science assessment, in classifying students’ expertise levels in scientific explanation. Our findings indicate that while pretrained language models such as BERT contribute to enhanced performance in language-related tasks within educational contexts, the incorporation of identifying domain-specific terms and extracting and substituting with their associated sibling terms in sentences through ontology-based systems can further improve classification model performance. Further, we qualitatively examined student responses and found that, as expected, the ontology framework identified and substituted key domain specific terms in student responses that led to more accurate predictive scores. The study explores the practical implementation of ontology in classrooms to facilitate formative assessment and formulate instructional strategies.
FEW Questions, Many Answers: Using Machine Learning Analysis to Assess How Students Connect Food-Energy-Water Concepts
Emily Royse, Amanda Manzanares, Heqiao Wang, and 10 more authors
There is growing support and interest in postsecondary interdisciplinary environmental education which integrate concepts and disciplines in addition to providing varied perspectives. There is a need to assess student learning in these programs as well as rigorous evaluation of educational practices,especially of complex synthesis concepts. This work tests a text classification machine learning model as a tool to assess student systems thinking capabilities using two questions anchored by the Food-Energy- Water (FEW) Nexus phenomena by answering two questions (1) Can machine learning models be used to identify instructor-determined important concepts in student responses? (2) What do college students know about the interconnections between food, energy and water, and how have students assimilated systems thinking into their constructed responses about FEW? Reported here are a broad range of model performances across 26 text classification models associated with two different assessment items, with model accuracy ranging from 0.755 to 0.992. Expert-like responses were infrequent in our dataset compared to responses providing simpler, incomplete explanations of the systems presented in the question. For those students moving from describing individual effects to multiple effects, their reasoning about the mechanism behind the system indicates advanced systems thinking ability. Specifically, students exhibit higher expertise for explaining changing water usage than discussing tradeoffs for such changing usage. This research represents one of the first attempts to assess the links between foundational, discipline-specific concepts and systems thinking ability. These text classification approaches to scoring student FEW Nexus Constructed Responses (CR) indicate how these approaches can be used, in addition to several future research priorities for interdisciplinary, practice-based education research. Development of further complex question items using machine learning would allow evaluation of the relationship between foundational concept understanding and integration of those concepts as well as more nuanced understanding of student comprehension of complex interdisciplinary concepts.
CohBERT: Enhancing Language Representation through Coh-Metrix Linguistic Features for Analysis of Student Written Responses
Heqiao Wang, and Xiaohu Lu
Computers and Education. In preparation 2024
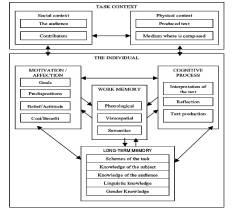
Genre-specific writing motivation in late elementary-age children: Psychometric properties of the Situated Writing Activity and Motivation Scale.
Gary Troia, Frank Lawrence, and Heqiao Wang
International Electronic Journal of Elementary Education (in review) 2024
This study evaluated the latent structure, reliability, and criterion validity of the Situated Writing Activity and Motivation Scale (SWAMS) and determined if writing motivation measured by the SWAMS was different across narrative, informative, and persuasive genres using a sample of 397 fourth and fifth graders. Additionally, differences in writing motivation and essay quality attributable to sample sociodemographic characteristics were examined. Overall, the narrative, informative, and persuasive subscales of the SWAMS exhibited acceptable psychometric properties, though there were issues related to unidimensional model fit and item bias. A significant amount of unique variance in narrative, informative, and persuasive writing quality was explained by motivation for writing in each genre. Although we did not observe genre-based differences in overall motivation to write using summative scores for each subscale, there were small but significant differences between narrative and informative writing for the discrete motivational constructs of self-efficacy, outcome expectations, and task interest and value. Consistent differences favoring girls and students without special needs were observed on SWAMS scores, apparently linked with observed differences in writing performance. Limitations of the study and suggested uses of the SWAMS are discussed.
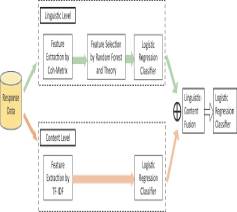
Is ChatGPT a Threat to Formative Assessment in College-Level Science? An Analysis of Linguistic and Content-Level Features to Classify Response Types
Heqiao Wang, Tingting Li, Kevin Haudek, and 5 more authors
In International Conference on Artificial Intelligence in Education Technology 2023
The impact of OpenAI’s ChatGPT on education has led to a reexamination of traditional pedagogical methods and assessments. However, ChatGPT’s performance capabilities on a wide range of assessments remain to be determined. This study aims to classify ChatGPT-generated and student constructed responses to a college-level environmental science question and explore the linguistic- and content-level features that can be used to address the differential use of language. Coh-Metrix textual analytic tool was implemented to identify and extract linguistic and textual feature. Then we employed random forest feature selection method to determine the best representative and nonredundant text-based features. We also employed TF-IDF metrics to represent the content of written responses. The true performance of classification models for the responses was evaluated and compared in three scenarios: (a) using content-level features alone, (b) using linguistic-level features alone, (c) using the combination of two. The results demonstrated that the accuracy, specificity, sensitivity, and F1-score all increased when we used the combination of two-level features. The results of this study hold promise to provide valuable insights for instructors to detect student responses and integrate ChatGPT into their course development. This study also highlights the significance of linguistic- and content-level features in AI education research.
@inproceedings{wang2023chatgpt,title={Is ChatGPT a Threat to Formative Assessment in College-Level Science? An Analysis of Linguistic and Content-Level Features to Classify Response Types},author={Wang, Heqiao and Li, Tingting and Haudek, Kevin and Royse, Emily A and Manzanares, Mandy and Adams, Sol and Horne, Lydia and Romulo, Chelsie},booktitle={International Conference on Artificial Intelligence in Education Technology},pages={171--185},year={2023},organization={Springer},}
The primary purpose of this study is to investigate the degree to which register knowledge, register-specific motivation, and diverse linguistic features are predictive of human judgment of writing quality in three registers—narrative, informative, and opinion. The secondary purpose is to compare the evaluation metrics of register-partitioned automated writing evaluation models in three conditions: (1) register-related factors alone, (2) linguistic features alone, and (3) the combination of these two. A total of 1006 essays (n = 327, 342, and 337 for informative, narrative, and opinion, respectively) written by 92 fourth- and fifth-graders were examined. A series of hierarchical linear regression analyses controlling for the effects of demographics were conducted to select the most useful features to capture text quality, scored by humans, in the three registers. These features were in turn entered into automated writing evaluation predictive models with tuning of the parameters in a tenfold cross-validation procedure. The average validity coefficients (i.e., quadratic-weighed kappa, Pearson correlation r, standardized mean score difference, score deviation analysis) were computed. The results demonstrate that (1) diverse feature sets are utilized to predict quality in the three registers, and (2) the combination of register-related factors and linguistic features increases the accuracy and validity of all human and automated scoring models, especially for the registers of informative and opinion writing. The findings from this study suggest that students’ register knowledge and register-specific motivation add additional predictive information when evaluating writing quality across registers beyond that afforded by linguistic features of the paper itself, whether using human scoring or automated evaluation. These findings have practical implications for educational practitioners and scholars in that they can help strengthen consideration of register-specific writing skills and cognitive and motivational forces that are essential components of effective writing instruction and assessment.
@article{wang2023writing,title={Writing Quality Predictive Modeling{:} Integrating Register-Related Factors},author={Wang, Heqiao and Troia, Gary A},journal={Written Communication},volume={40},number={4},pages={1070--1112},year={2023},publisher={SAGE Publications Sage CA{:} Los Angeles, CA},}
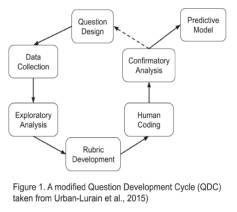
Development of a Next Generation Concept Inventory with AI-based Evaluation for College Environmental Programs
Kevin Haudek, Chelsie Romulo, Steve Anderson, and 8 more authors
In AERA Annual Meeting, Chicago, IL: American Educational Research Association 2023
Interdisciplinary environmental programs (EPs) are increasingly popular in U.S.universities, but lack consensus about core concepts and assessments aligned to these concepts. To address this, we are developing assessments for evaluating undergraduates’ foundational knowledge in EPs and their ability to use complex systems-level concepts within the context of the Food-Energy-Water (FEW) Nexus. Specifically, we have applied a framework for developing and evaluating constructed response (CR) questions in science to create a Next Generation Concept Inventory in EPs, along with machine learning (ML) text scoring models. Building from previous research, we identified four key activities for assessment prompts: Explaining connections between FEW, Identifying sources of FEW, Cause & Effect of FEW usage and Tradeoffs. We developed three sets of CR items to these four activities using different phenomena as contexts. To pilot our initial items, we collected responses from over 700 EP undergraduates across seven institutions to begin coding rubric development. We developed a series of analytic coding rubrics to identify students’ scientific and informal ideas in CRs and how students connect scientific ideas related to FEW. Human raters have demonstrated moderate to good levels of agreement on CRs (0.72-0.85) using these rubrics. We have used a small set of coded responses to begin development of supervised ML text classification models. Overall, these ML models have acceptable accuracy (M= .89, SD= .08) but exhibit a wide range of other model metrics. This underscores the challenges of using ML based evaluation for complex and interdisciplinary assessments.

 FEW Questions, Many Answers: Using Machine Learning Analysis to Assess How Students Connect Food-Energy-Water ConceptsNature (in review) 2024
FEW Questions, Many Answers: Using Machine Learning Analysis to Assess How Students Connect Food-Energy-Water ConceptsNature (in review) 2024 CohBERT: Enhancing Language Representation through Coh-Metrix Linguistic Features for Analysis of Student Written ResponsesComputers and Education. In preparation 2024
CohBERT: Enhancing Language Representation through Coh-Metrix Linguistic Features for Analysis of Student Written ResponsesComputers and Education. In preparation 2024 Genre-specific writing motivation in late elementary-age children: Psychometric properties of the Situated Writing Activity and Motivation Scale.International Electronic Journal of Elementary Education (in review) 2024
Genre-specific writing motivation in late elementary-age children: Psychometric properties of the Situated Writing Activity and Motivation Scale.International Electronic Journal of Elementary Education (in review) 2024